Download Source Code: TwitterWorkflowElementsSample.zip
Crawling or sending multiple requests to social media service APIs must often handle with API quotas or limits. Most of the time this data needs further processing and therefore a complex processing logic. For example Twitter where short URLs are in the status. This sample shows how Twitter can be queried without violating API limits and how the short URLs are resolved in a uniform manner by using the Crawler-Lib Engine.
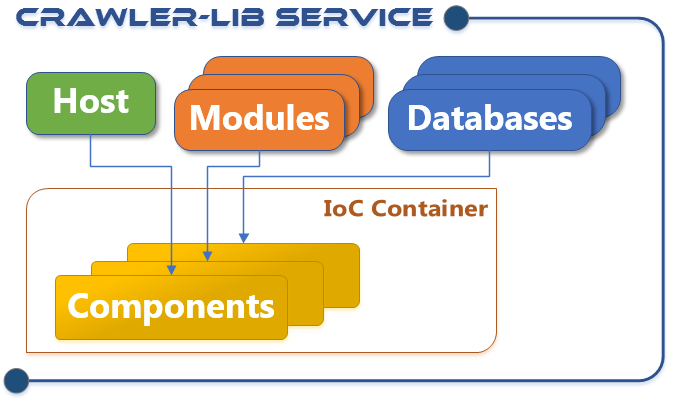
The Crawler-Lib Engine is a workflow enabled multipurpose background task processor. In contrast to dedicated web crawlers the task workflow can be freely defined and is not limited to HTTP requests. In this article shows how the Twitter library LinqToTwitter is used to build Twitter workflow elements for the Crawler-Lib Engine and to use it to retrieve a user timeline and analyze all short URLs in the tweets.
This code sample is extracted from a real world project called Social Media Assistant which uses the Crawler-Lib Engine to perform complex background tasks. Crawler-Lib has not yet provided workflow elements to access Twitter yet, but it is not very complicate to integrate any existing library like LinqToTwitter:
Building the Twitter Workflow Element
To use Twitter in the Crawler-Lib Engine the creation of a workflow element for every type of operation is recommended. We use the LinqToTwitter library to process the twitter requests. Any library with an callback or task based async mode can be used to build workflow elements. A processable workflow element has a StartWork() and a Process() . The start work method must ensure that the element is processed after the operation completes by calling RegisterWorkflowChildForProcessing(). In case of awaitable operations with tasks this is simply done with ContinueWith() on the task:
private Task<List<Status>> operation;
this.operation = query.ToListAsync(); this.operation.ContinueWith(c => this.Task.RegisterWorkflowChildForProcessing(this));
The LinqToTwitter library generates the request in form of a LINQ query which is generated in the StartWork() method of the workflow element:
protected override void StartWork()
{
using (var twitterCtx = new TwitterContext(this.Config.Authorizer))
{
var query =
twitterCtx.Status.Where(
tweet =>
tweet.Type == StatusType.User && tweet.Count == this.config.Count
&& tweet.IncludeContributorDetails == this.config.IncludeContributorDetails
&& tweet.TrimUser == this.config.TrimUser);
if (!string.IsNullOrEmpty(this.config.ScreenName))
{
query = query.Where(tweet => tweet.ScreenName == this.config.ScreenName);
}
if (this.config.ID != null)
{
query = query.Where(tweet => tweet.ID == this.config.ID.Value);
}
if (this.config.MaxID != null)
{
query = query.Where(tweet => tweet.ID == this.config.MaxID.Value);
}
if (this.config.SinceID != null)
{
query = query.Where(tweet => tweet.ID == this.config.SinceID.Value);
}
if (this.config.UserID != null)
{
query = query.Where(tweet => tweet.ID == this.config.UserID.Value);
}
this.operation = query.ToListAsync();
this.operation.ContinueWith(c => this.Task.RegisterWorkflowChildForProcessing(this));
}
}
After the operation completes it is registered for processing. The next free worker thread picks it up and calls Process(). In the process method are various handers executed:
protected override void Process()
{
if (this.operation.IsFaulted)
{
this.MarkFailed(this.operation.Exception);
}
else if (this.operation.IsCompleted)
{
this.Statuses = this.operation.Result;
}
switch (this.ProcessingInfo.InfoVerbosity)
{
case ProcessingInfoBase.VerbosityEnum.Data:
{
this.ProcessingInfo.Statuses = this.Statuses == null ? new Status[0] : this.Statuses.ToArray();
}
break;
}
try
{
if (this.ProcessingInfo.Success)
{
if (this.Config.Successful != null)
{
this.Config.Successful.Invoke(this);
}
if (this.Config.Finally != null)
{
this.Config.Finally.Invoke(this);
}
if (this.awaiter != null && this.Config.AwaitProcessing.HasFlag(AwaitProcessingEnum.Success))
{
this.awaiter.ExecuteContinuation(this);
}
}
else
{
if (this.Config.Failed != null)
{
this.Config.Failed.Invoke(this);
}
if (this.Config.Finally != null)
{
this.Config.Finally.Invoke(this);
}
if (this.awaiter != null && this.Config.AwaitProcessing.HasFlag(AwaitProcessingEnum.Failed))
{
this.awaiter.ExecuteContinuation(this);
}
}
}
catch (Exception ex)
{
this.MarkFailed(ex);
throw;
}
}
These are the basics workflow elements for the integration of arbitrary APIs. Now let’s use the new element in a task.
Building the Read User Timeline Task
We have several objectives here. First of all we don’t want Twitter to block our application because we violate API limits. Second we don’t want to flood the short URL service with too many requests. Third we want to retrieve the link information in parallel to keep the processing time of this task low.
The get user timeline request can return 200 statuses (Tweets). If every status has an URL or two we have 200-400 web requests. If we don’t send the requests in parallel, it can take a while until the links are analyzed. Here is the implementation:
public override async void StartWork()
{
base.TaskResult = new ReadTwitterTimelineTaskResult();
this.TaskResult.ScreenName = this.TaskRequest.ScreenName;
this.TaskResult.Items = new List<TwitterStatusItem>();
var authorizer = new SingleUserAuthorizer
{
CredentialStore =
new SingleUserInMemoryCredentialStore
{
ConsumerKey = this.TaskRequest.ConsumerKey,
ConsumerSecret = this.TaskRequest.ConsumerSecret,
AccessToken = this.TaskRequest.AccessToken,
AccessTokenSecret = this.TaskRequest.AccessTokenSecret
}
};
UserTimeline userTimeline = null;
try
{
await new Limit(
new LimitConfig { LimiterName = "TwitterLimiter",
StartWork = limited =>
{
userTimeline = new UserTimeline(authorizer, this.TaskRequest.ScreenName);
} });
var analyzedResult = await this.AnalyzeTwitterStatus(userTimeline.Statuses);
this.TaskResult.Items = analyzedResult.Result;
}
catch (Exception exception)
{
if (userTimeline != null)
{
userTimeline.MarkFailed(exception);
}
}
}
Our new UserTimeline workflow element is executed within a Limit workflow element which enforces the Twitter limits. The limits are added to the Crawler-Lib Engine after creation. There are multiple possibilities how to configure the limiter. Assuming we have user authentication and a limit of 180 requests/ 15 minutes the first configuration allows the 180 requests (in parallel) and blocks the execution of further requests for 15 minutes:
engine.AddLimiter(
new QuotaLimiter(
new QuotaLimiterConfig
{
Name = "TwitterLimiter",
LimitedThroughput = 180,
LimitedThroughputInterval = TimeSpan.FromMinutes(15),
LimitedThroughputWorkingMax = 180,
LimitedThroughputIdleMax = 180,
}));
The second configuration allows one request every 5 seconds so that the limit of 180 requests / 15min won’t be broken.
engine.AddLimiter(
new QuotaLimiter(
new QuotaLimiterConfig
{
Name = "TwitterLimiter",
LimitedThroughput = 1,
LimitedThroughputInterval = TimeSpan.FromSeconds(5),
LimitedThroughputWorkingMax = 1,
LimitedThroughputIdleMax = 1
}));
These implementations use throughput limitation to delay requests. There are much more possibilities to do this.
After the User timeline is received, it should be analyzed and the short URLs should be resolved. This is done in the AnalyzeTwitterStatus() method:
private CalculateResult<List<TwitterStatusItem>> AnalyzeTwitterStatus(List<Status> statusses)
{
var result = new Calculate<List<TwitterStatusItem>, TwitterStatusItem>(
calc =>
{
calc.Result = new List<TwitterStatusItem>();
foreach (var status in statusses)
{
var item = new TwitterStatusItem { Published = status.CreatedAt, ScreenName = status.User.ScreenName, Text = status.Text };
calc.AddItem(item);
var links = ExtractLinksFormText(item.Text);
this.GetLinkMetadatas(links, list => item.Links = list);
}
});
return result;
}
This method uses a Calculate workflow element to assemble a result from multiple parallel requests in a thread save manner. The CalculeateResult type makes this method awaitable in the calling context, as seen before. Two methods are used to analyze the short URLs in the status text. First the ExtractLinksFormText retrieves all URLs from the text:
public static List<Uri> ExtractLinksFormText(string text)
{
var result = new List<Uri>();
var linkParser = new Regex(@"b(?:https?://|www.)S+b", RegexOptions.Compiled | RegexOptions.IgnoreCase);
foreach (Match match in linkParser.Matches(text))
{
result.Add(new Uri(match.Value, UriKind.RelativeOrAbsolute));
}
return result;
}
Second the GetLinkMetadatas() resolve the short URL and retrieve some data from the page:
public CalculateResult<List<LinkMetadata>> GetLinkMetadatas(IEnumerable<Uri> links, Action<List<LinkMetadata>> successHander)
{
var result = new Calculate<List<LinkMetadata>, LinkMetadata>(
new CalculateConfig<List<LinkMetadata>, LinkMetadata>
{
Successful = calc =>
{
if (successHander != null)
{
successHander.Invoke(calc.Result);
}
},
StartWork = calc =>
{
calc.Result = new List<LinkMetadata>();
var index = 0;
foreach (var link in links)
{
var pos = index++;
new Limit(
new LimitConfig
{
LimiterName = "WebsiteRequestLimiter",
StartWork = async limited =>
{
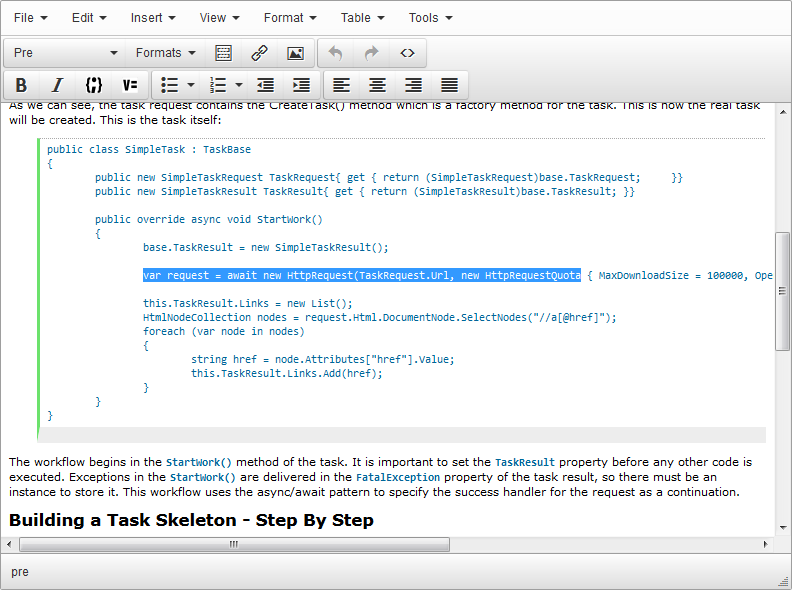
var request =
await new HttpRequest(
new HttpRequestConfig
{
Url = link,
Quota = new HttpRequestQuota(),
AutoPerformRedirects = true
});
calc.SetItem( pos, GetLinkMetadata( request));
}
});
}
}
});
return result;
}
The HttpRequest performs the redirects and the target page is analyzed. A notable feature of the Calculate workflow element is the SetItem() method which allows to set the item on a specific position in the list in a thread save manner. It expands an empty list, so that the position (index) become accessable. This is important here because we want to keep the ordering of the links, regardless which request completes first. If we had used AddItem() the results the results would have the same ordering as the requests are completing. Keep in mind all of these requests are executed in parallel. Only the Limit workflow element controls the throughput or how many requests are executed really in parallel.
The Crawler-Lib Engine provides new opportunities to design background tasks. Access to arbitrary APIs can be integrated in the workflow with little effort. The various workflow control elements like Limit and Calculate give a fine gained control over complex operations.
Using the Code
To run this sample you must register an application. We recommend to add an test Twitter account for this purpose. You must have a mobile phone number associated with your account to create an Twitter App. Applications are registered at https://apps.twitter.com/.
After you have created your applications generate your keys and access tokens. Copy the Consumer Key, Consumer Secret, Access Token and Access Token Secret into the initializers for the static fields. This is done in Progam.cs in the Mein() method.
This sample crawls only one twitter user. You may add more of them to see the limiters punch in. It has no full blown scheduler. If you intend to implement this in a real application, please read:
- Website Crawler Sample for the scheduler implementation
http://www.crawler-lib.net/csharp-code-samples-engine-website-crawler - Workflow Elements Sample for the use of the different workflow elements
http://www.crawler-lib.net/csharp-code-samples-engine-workflow